I’ve written previously about the effectiveness and extensibility of Expected and Actual as a mental model to understand usability. As a reminder, when the actual experience we offer users matches the expected experience they bring to the interaction, the user experiences no friction, and hence, usability is considered good.
In most cases, we accept “expected” where we find it and do our best to match it with “actual”. This is an important part of usability writings like Don Noman’s “Design of Everyday Things” and Steve Krug’s “Don’t Make Me Think”, which help us understand how users have formed their expectations and how we can map software systems to those expectations.
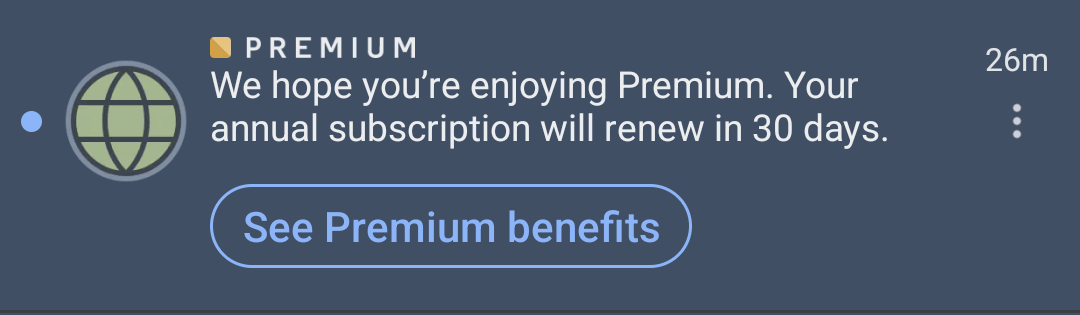
I recently experienced an update from LinkedIn, however, that helped me appreciate how “expected” can be influenced. On its surface, this update resembles others you may have seen - an email, perhaps, or an SMS you opted into a couple years ago, but this one struck me as just the right amount of notification in just the right place.
An important part of making this work is the channel in which this update is presented. This update displayed right in the normal LinkedIn updates feed, which made it likely I’d see it, and also made it feel less spammy than a separate notification out of the blue.
It’s also possible that I appreciated this notification more because not a week prior to this, I had a UX experience that felt very different. My experience began with an alert from my bank. Had I just authorized a payment of [x] from Amazon? I didn’t recognize the amount, and checked my Amazon account to see if this corresponded to any recent orders. It didn’t, so I answered as such to my bank, and they immediately paused my card. It was late, and I didn’t feel like finding out if my bank had extended hours support, so I decided to deal with it in the morning. Of course, I forgot about it until lunch, when I reached for my card and remembered it wasn’t going to work. A call to the bank was next, and the first thing they asked was whether I was a prime member, and might this be a renewal charge. Sure enough - that was it. Still no idea why it triggered the bank’s fraud algorithm, but the overall experience from soup to nuts felt crude and disrespectful - especially by comparison to the LinkedIn experience I saw later.
As always, the lesson here is best-applied broadly. If you have an opportunity to form expectations anywhere in your UX, you’re far more likely to be able to meet them, and met expectations are gold in UX.
Earlier this week, I had a very short, very disconcerting Teams meeting. Shortly after the meeting began, I and the other participant noticed an AI bot show up. Neither of us were aware we’d invited it, which as you can imagine, was puzzling and more than a little disconcerting to both of us. Believing discretion is the better part of valor, we both agreed to abandon the meeting, and I did some googling.
It turns out it was my fault (ultimately) the bot showed up in the meeting. Last week, I’d attended a meeting where one of the hosts had invited this bot to take notes. Following the meeting, the bot sent a meeting summary to all the attendees (so far, so good). Having missed a specific point I wanted to look up, I tried accessing the meeting transcript, and was prompted to create an account.
What I hadn’t seen was the (in my opinion) extremely aggressive default behavior on the part of this platform to just go ahead and invite itself to any and all of my future meetings – even those in which I was a guest!
In hindsight, there are at least a couple of lessons to be learned from this experience. First, as a consumer, all those damned EULAs actually matter. Choose your connections with care, and consider the permissions you bestow on apps. It may be a bit inconvenient to pass on an app that seems a bit greedy, but every once in a while, it just may save your bacon.
The other lesson is offered from the perspective of a product designer, and it requires a bit of empathy with respect to your user / audience. Please consider - realistically - the behaviors your users might actually expect of your product. In the case of this meeting note-taker, it’s appropriate to have the bot offer its services when I create meetings. Ideally, I’d have liked to see something interactive the first time the bot has the opportunity to hop on a meeting, and if I elect, “yes”, I think it would be appropriate to ask if I want that to be the behavior for future meetings. Offer a service to me, but don’t surprise me by joining behind my back!
I also believe there should have been distinct behaviors for meetings I host vs. meetings I join as a guest. In my opinion, it would be appropriate for the bot to ask to attend any meeting I join as a guest. Finally, when joining, the behavior I saw in the meeting was very poorly-sequenced. When the bot joined my meeting unexpectedly, it hung around for a good 30 seconds before offering anything in the chat window – a definite faux-pas. I’d expect to immediately see a message indicating who invited the bot and offering actions to stop the recording if desired. Having this message show up half-a-minute into the meeting is no bueno.
The era of AI is upon us. Platforms can now do more for us than ever before, and what we’ve seen so far is just the beginning. However, usability / UX practices need to be engaged for this journey so that these capabilities can be seen as helpful and not subversive or destructive. Help you expect will always be welcome, but please beware helping in ways that aren’t expected - at best, this will be interpreted as “handling”, and at worst, it’s an unwelcome intrusion. The first interactions you have with a new customer are precious - don’t botch them and risk losing a customer forever by overstepping your welcome!
Commonly, when people think "user experience", they think about screen designs. Apps, web pages, Figma -- all that stuff. The shift from UI design to UX alone is a nod to this practice being more than skin-deep, but I still think a lot of the deeper behavioral aspects of user satisfaction are lost on many -- especially people who have only a casual interest in UI/UX.
I believe there are clues all around us, though, that we can take advantage of if we pay attention. I'll begin with the premise / reminder that real usability is completely invisible. You can only see usability by the absence of impediments to usability. In short, a system is usable when it does exactly what a user expects, even if they can't articulate those expectations.
One of the best examples of invisible usability can be found in Visual Studio, which has been a market-leading IDE for decades now. Built by developers for developers, they've gotten a lot of things right, and even though you're probably not building a tool for use by developers, some of these lessons likely can apply for you, too.
Starting Fresh
Right off the bat, Visual Studio shows its usability by setting users up to be successful when working with a new project. Pick any template you like in Visual Studio, create a new project from it, and it will build successfully. While it might not seem like a big deal, it makes a lot of difference for a new user learning one of these technologies. The ability to start from a solid foundation gives that user confidence to build on that new solution.
What's the lesson? Be aware of the "getting started" experience for your users. Anything you can do to start a user more quickly and with more confidence will help them start using your software with confidence. When users get started with confidence and gain momentum, they're more likely to persevere a bit more if they get stuck later, too.
Save Always
Another subtle way Visual Studio helps is one you probably never gave a second thought. No matter what state your working files are in, you'll never mess one up so badly that Visual Studio won't let you save your work:
A more elegant take on this is to save automatically, so if something goes really wrong, you have a recovered version of your work (which Visual Studio obviously does). Note that automatically saving can actually introduce some small usability hiccups of its own, but that's a problem for another day.
What's the lesson? Document-based applications like Visual Studio and office apps (spreadsheets, docs and the like) typically consider this sort of behavior table stakes these days, and it's not likely you're building one of these, but watch out for behaviors that cause a user to not be able to save work-in-progress. In a UI, you may run into this if you've got a bunch of required fields on a page, and as the field count goes up (and maybe the page count, too), expect that your users' frustration level will go up, too.
It's actually a lot more likely that you'll run into this problem in your APIs. For example, here's a simple method I used in a post about fluent validation:
public ActionResult CreateDealer(Dealer dealer)
{
Guard.Against.AgainstExpression<int>(id => id <= 0, dealer.Id, "Do not supply ID for new entity.");
var dvalidator = new DealerValidator();
var result = dvalidator.Validate(dealer);
if (result.IsValid)
{
_sampleData.Add(dealer); // SaveChangesAsync() when working with an actual data store
return CreatedAtAction(nameof(CreateDealer), new { id = dealer.Id }, dealer);
}
else
{
return BadRequest(result);
}
}
While this method effectively validates inputs, the return results to the user aren't especially helpful, and as an object like this scales up in size, it's more likely that a consumer will have partial inputs that don't pass all validation criteria. Rather than preventing this from saving altogether, consider structuring an object like this so that as many values as possible are optional for saving -- even if they're needed in order to have a "valid" object.
In this simple example, we can create a result type that appends a ValidationResult property to the model. We'll return this instead of the "naked" object to show the validation propertied next to the model. The result object is preferrable to embedding a ValidationResult in the model because this keeps the request intact -- there's no reason for the ValidationResult to be part of the CRUD requests.
public class ModelValidationResult<M, V> where V : AbstractValidator<M>, new()
{
public ModelValidationResult(M model)
{
this.Model = model;
}
public M Model { get; private set; }
public FluentValidation.Results.ValidationResult ValidationResult { get; set; }
public bool Validate()
{
V validator = new V();
this.ValidationResult = validator.Validate(this.Model);
return ValidationResult.IsValid;
}
}
With Validate in the Dealer object, the controller method also becomes a bit simpler:
public ActionResult CreateDealer(Dealer dealer)
{
Guard.Against.AgainstExpression<int>(id => id <= 0, dealer.Id, "Do not supply ID for new entity.");
ModelValidationResult<Dealer, DealerValidator> res = new ModelValidationResult<Dealer, DealerValidator>(dealer);
res.Validate();
_sampleData.Add(dealer); // SaveChangesAsync() when working with an actual data store
return CreatedAtAction(nameof(CreateDealer), new { id = dealer.Id }, res);
}
Note that I left the guard clause in place here -- there will still be some validations that really need to prevent saving bad data, but now that these changes are in place, it's possible to save an object with incomplete data.
This technique won't work in all cases, but consider it if you can support saving objects with a minimal set of data and check for a fully-populated object later.
And more!
If you view Visual Studio with an eye to borrowing UX techniques, you'll see more lessons like these - the Dynamic Validation example I covered earlier is an example. Since you're probably not building an IDE or even a tool for developers, you'll need to interpret some of the techniques liberally, but I assure you the lessons are there. You may also see some negative usability examples -- in fact, sometimes these are easier to see because they get in our way and draw our attention.
I'm a fan of simple hooks to summarize complex ideas, and one of my favorite go-to's is simple, memorable and versatile:
Expected == Actual
Not much to look at by itself, but I've gotten a lot of mileage out of this in some useful contexts. You probably recognize one of the most obvious applications immediately: testing / QA. We're well-trained in applying expected == actual in testing, and most bug-reporting contexts will define a bug as a scenario in which actual behavior doesn't match expected behavior.
Even in this simplest application, all the value here is in how we exercise the framework, and I promise if you really work this equation, you'll have a better handle on bugs immediately. Of the two sides of this equation, "expected" usually seems easier, but is almost always more difficult becuase we most of our expectations are unspoken. If I had a dime for every bug report I've seen where "actual" was well-documented but "expected" existed only in the mind of the reporter, for instance, I'd be writing this from a beach in Hawaii.
Of course, that's where the exercise begins to get interesting. "What were you expecting" is a great place to start here. If you can trace expectations to real documented requirements, it's a short conversation (perhaps followed by another conversation to see why that scenario was missed in autometed testing). It's not unheard-of, though for these bugs to occur in scenarios that weren't explicitly called-out in requirements. If this is the case, be sure to examine "expected" to see if it's reasonable for most users to expect the same thing under those conditions, which is a great segue to my next favorite application of expected == actual.
I'm of the opinion that expected == actual is also a pretty good foundation for understanding usability. I touched on this recently in a post about API usability, and it holds true generally, I believe. In that post, I referenced Steve Krug's Don't Make Me Think, which is both an excellent book and another great oversimplification of UX. Both of these are built on the premise that whenever an application does what a user expects it to do, they don't have to think about it, and they consider it usable.
Mountains have been written about how to accomplish this, of course, and I'm not going to improve on the books that talk about those techniques, but as I pointed out with resepct to API usability, consistent behavior goes a long way. Even devices or applications we consider highly usable have a short learning curve, but one a user is invested in that curve, it's tremendously helpful to leverage that learning consistently -- no surprises!
A final consideration that applies in both these areas - when you find a case where "expected" really isn't well-definded yet, and can't be easily-derived based on other use cases (consistency), this is a golden opportunity. Rather than just taking their version of "expected" at face value, ask why they expected that (when possible). You probably won't be able to invest in a full "nine-why's" exercise, but keep that idea in mind. The more you understand about how those expectations formed, the more closesly you can emulate that thinking as you project other requirements.
Besides these examples, where else might you be able to apply "expected vs. actual"?
It's hard to believe that REST is over twenty years old now, and although the RESTful style of designing APIs isn't specifically limited to JSON payloads, this style has become associated with transformation from SOAP/XML to a lighter-weight style better-suited to web applications.
The near ubiquity of REST at this point can allow us to slip into some designs that I don't believe are particularly well-suited for this style of API. In this article, I'm going to briefly examine scenarios that work well in a RESTful style -- and why -- and for scenarios that aren't well-suited for REST, we'll look at some alternatives.
A closer look at REST
Most software developers will recognize a RESTful API, but for many, this is a "I'll know it when I see it" recognition. There's no shortage of defintions on the web for REST APIs, and I'd encourage you to browse a few to see what commonalities emerge. Among the most common traits are statelessness, cacheability, and most importantly, a resource-based interface.
The "resource-based interface" is key here - this is the bedrock of the "style" of a RESTful interface. Let's work through a simple example -- say, a car dealer web service. The GET methods here are predictable given a Dealer type:
Here, we've got a list of dealers and a GET for one dealer specified by ID. This is REST at its simplest. The resource here is the Dealer, and much of the fluency of REST comes from being able to predict not only how these APIs will work, but also the remainder of the major operations we'd expect. So, here, GET /Dealer will return a list of all Dealers known to this service, and GET /Dealer/{id} looks for just one.
Without even looking at the API spec, we know what most of the remaining operations should be for Dealers:
Add - we expect to be able to add new dealers with a POST and a dealer model.
Edit- we expect to POST to /Dealer/{id} with a dealer model to edit that entity.
Delete - not all API's will support this, but for if this one does, it would be a DELETE action at /Dealer/{id}.
Patch - again, where it's supported, it allows updates by specifying only fields that have changed, and again, we'd expect to find it at /Dealer/{id}.
A big theme contributing to the predictability of REST (which is one of the major appeals) is that you (the designer / developer) determine the resource - Dealer in this case - and the main operations shown here are largely implied. You design the noun, and REST supplies the verbs (they're even commonly referred to as HTTP verbs). Another way to look at these is to consider the resource as an object that's normally at rest (aka REST). Changes to this resource happen only when an HTTP verb acts on the resource.
The tendancy for these resources to change only when impacted by an HTTP verb via this API also contributes to the effectiveness of caching in a RESTful API, as you'll recall from the definitions referenced earlier.
Less universal, but very helpful, in my opinion, for a RESTful interface, is for the resource to behave atomically. Admittedly, the example we're using here is ultra-simplified, but when we act on a Dealer, the closer we can be to these guidelines, the easier it is for API consumers to predict how the API will perform (API's have usability, too!). These guidelines are based on the premise that REST is a web-native design, and developers will expect the API to behave as they'd expect other HTTP resources to behave.
Operations are deterministic and cohesive. Ideally, each operation should stand on its own. Domain objects manipulated with these methods will certainly be subject to validation -- as in the url validation shown here. This is a local problem with the specific parameters sent on this call, and most API developers should have no trouble sorting out what they need to do to make this call work.
Avoid "bell-ringing". A REST operation should be done when the status is returned to the caller. There will be cases where a changed resource will kick off a workflow, but monitor these carefully. If I kick off a workflow because I changed a resource and I don't care about the workflow, it may still be ok, but watch out for cases where a caller kicks off a workflow that they care about -- this may not be suitable for a simple REST-syntax method.
Permissions apply to the whole resource. Imagine that the combination of resource and verb is all the information you've got to determine whether you're authorizing the operation. A user in a given role should ideally be able to create / edit / delete a resource or not.
Complications arise
As API operations become more complex, it's common to see use cases that bend the ideals of those simple REST operations. Many of these nuanced use cases can be shoehorned into a REST-like syntax. This is quite common for simple variations on verbs like Search or modifications or overloads of Add/POST or Edit/PUT. Watch for factors like these - they signal you're moving into API scenarios that require some special attention, and may be clues that you're not really working with RESTful methods anymore:
Methods refer to a verb other than normal REST verbs. Some of these (ex: search) can be very compatible with a RESTful syntax and style. If you start running into bespoke verbs, consider switching to an RPC-like call. This can still live in the same API and use JSON for transport -- it's just going to be more verb-forward than noun-forward. These calls are invaluable as your API becomes more complex, but be aware that you give up some of the automatic usability of noun-based REST because these bespoke verbs are unique to your use case and application!
Nouns begin to become complex. Consider a trivially-simple car dealer model:
public int Id { get; set; }
public string? Name { get; set; }
public string? Description { get; set; }
public string? Website { get; set; }
This ultra-simple model works great in a RESTful API, but it clearly doesn't have enough detail to be useful. As soon as you add more detail / complexity -- in this case, an array of brand affiliations -- the model becomes more difficult to use in the API. This example works great in the domain model, but with the addition of one new BrandAffiliation collection, the JSON structure becomes much more difficult for an API user / developer:
A more friendly approach for the API user would likely be a nested REST structure that permits a get or post like /dealer/{dealerid}/parent/{parentid}. If this is starting to look like an OData style, that's great - that's a direction we'll explore more in the future!
Beyond Simple REST
In some cases, complex or complicated scenarios may be better-suited with an RPC-style method. These can live in a predominantly RESTful API - nothing about these is incompatible with the API specifications governing REST, but I think it's helpful to be aware when you're moving away from a pure REST model. Amazon has published a great summary of REST vs. RPC, and it's a great place to start in considering these styles. For our purposes, it's important to recognize that "RPC-like" in style does not imply an actual RPC API!
As use cases evolve beyond that simple REST/OData-like style we looked at earlier, here are some specific places where "simple REST" may not have enough gas in the tank:
Verb-centric operations -- APIs where nouns participate, but operations are more about what's happening with those objects. These can be good places to explore those RPC-like calls.
Operations tying multiple objects or object types together (likely in a non-heirarchical way). In some cases, graph-ql APIs can fall in this category.
Anything that begins to take on state-machine characteristics -- I consider this a special form of verb-centric.
Events. Depending on your use case and how deep you're diving into the event pool, these could wind up looking RPC-like or you may be interested in something like Async API.
In all these cases, be sure to be aware of discoverability and predictabilty of your API. In many cases, it can be worth shoehorning an operation into a noun-centric REST call for the sake of consistency. I'll explore some of these nuances in future posts, including places where CQRS meets events and API styles.
In the meantime, try paying attention to nouns & verbs in your API and see if that helps guide some decisions about API style.
Usability has a long history in software. In fact, as I sat down to pen these words, I googled "history of usability ux" and turned up some scholarly articles going back over 100 years. Too far. In software, you can't go wrong starting with Apple, which puts the origin of UX in the mid 90's. Better.
But for much of this time, we've tuned in to software usability as experienced through our user interfaces by end-users. Today, there's more to usability than user interface design, and I'd like to broaden the discussion a bit.
Usability? What usability?
When you think about great user experiences, typically, we don't consider them to be great user experiences unless we start comparing them to lesser experiences. I believe this is a big clue into how we can apply UX more universally. I really think a lot of usability boils down to doing what a user is expecting you to do... so when you do it, most users will never even notice.
Think about it - when's the last time you gave a passing thought to usability for an application that was already behaving the way you wanted? There are scores of great books on how to achieve usability (I love Steve Krug's Don't Make Me Think, and Don Norman's The Design Of Everyday Things), but I really believe if you can manage to do what the user is expecting you to do, you're typically in pretty good shape.
The changing landscape of applications
Next, let's look at changes in applications and application design. You can probably see where this is going. Whereas once the only users of our applications were end-users operating via a Windows or web interface, cloud-native applications based on microservice architecture rely heavily on APIs to orchestrate, integrate and extend functionality. In many cases, APIs are the interfaces for services, and developers are our users. In this sense, APIs are the interface, and the user experience (UX) is found in the ease-of use of these APIs.
And what is it about an API we'd consider more usable? As with the generalized case above, I think the ultimate yardstick is whether the API behaves the way a developer would expect. I believe the popularity of RESTful APIs, for instance, isn't just because JSON is easy to work with -- it's because a well-written RESTful API is discoverable and predictable.
Note that discoverable isn't the same as documented - even correctly documented, which never happens. Discoverable starts with tools like swagger that expose live documentation of API methods and objects, but it connects with predicatable in an important way: as developers engage with your API and discover how some of it works, consistent behavior and naming creates predicability. When these two factors are combined, they reinforce one another and create an upward spiral for developers in which learning is rewarded and also helps future productivity. And yes - this exact relationship is part of understanding usability in a visual / UX context, as well.
Watch for more posts on API conventions and style soon, and watch for the ways these ideas support one another and ultimately contribute to Krug's tagline: Don't make me think!
Software developers are a clever lot, and prone to bouts of creativity every once in a while. It turns out these are essential traits when building software, but cleverness also needs to be must be tempered when it impacts the user-facing parts of your software.
(Bugzilla's "no results found" message -- please don't do this)
Case in point: Bugzilla's search results page. This is what happens when you try searching for something in Bugzilla and it doesn't find any results. It's supposed to be funny -- the misspelling is, in fact, intentional.
But it's not funny. It's really, really not funny. It's not funny for two very specific and very important reasons.
Reason 1: Usage context. If any Bugzilla user ever sees this message, it's because he failed at the task he was trying to accomplish. Since the message exists solely to explain to the user that he failed, it's pretty reasonable to assume that the user might not be in the best of moods already. I know I wasn't.
Reason 2: Product context. If you've not already had the pleasure of using Bugzilla, let me fill you in on its search capabilities: they suck. Like, searching in Bugzilla is not only unpleasant, it's also unfruitful way too often. It's the best reminder you're likely to see about why Google won the search wars -- it's because everything else used to work like Bugzilla. So when your (otherwise excellent) product has a critical flaw, such as searching in Bugzilla, it might be best to not choose that specific part of your product to try to crack a funny. Just sayin'.
The lesson in all this? Somewhere on any product team, there needs to be a voice of reason who's looking at context stuff like this and deciding when it's time to be funny, and when it's not.